
Lectures
You can download the lectures here. We will try to upload lectures prior to their corresponding classes. Future lectures listed below likely have broken links.
-
 01 - Intro to Deep Learning and Course Logistics
01 - Intro to Deep Learning and Course Logistics
tl;dr: We will introduce the topic of deep learning, a bit about it's history, and what impact it has had. Then we'll go over the course logistics, the lecture topics, problem sets and the mid-term and final projects.
[slides] [Jupyter Notebook]
Unfortunately the recording failed for this lecture. Will re-record it at some point.
Suggested Readings:
- UDL Chapter 1
-
 02 - Supervised Learning
02 - Supervised Learning
tl;dr: We go a little deeper into supervised learning, introducing terminology and illustrating with a simple example of a linear model.
[slides] [lecture recording] [Jupyter Notebook]
Suggested Readings:
- UDL Chapter 2
-
 03 - Shallow Networks
03 - Shallow Networks
tl;dr: In this lecture we consider networks with one layer of hidden units and explore their representational power.
[slides] [lecture recording]
Suggested Readings:
- UDL Chapter 3
-
 04 - Deep Networks
04 - Deep Networks
tl;dr: We dive into deep networks by composing two shallow networks and visualizing their representational capabilities. We then generalize fully connected networks with two and more layers of hidden units. We'll compare the modeling efficiency between deep and shallow networks.
[slides] [lecture recording]
Suggested Readings:
- UDL Chapter 4
-
 05 - Loss Functions
05 - Loss Functions
tl;dr: We reconsider loss functions as a measure of how well the data fits to parametric probability distribution. We show that for univariate gaussian distributions we arrive back at least squares loss. We then introduce the notion of maximum likelihood and see how we can use that to define loss functions for many types data distributions. We cover some examples and then show how to generalize. This is a key topic to aid you in applying deep learning models to new types of data.
[slides] [lecture recording]
Suggested Readings:
- UDL Chapter 5
-
 06 - Fitting Models
06 - Fitting Models
tl;dr: In this lecture we look at different ways minimizing the loss function for models given a training dataset. We'll formally define gradient descent, then show the advantages of stochastic gradient descent and then finally see how momentum and normalized gradients (ADAM) can improve model training farther.
[slides] [lecture recording] [lecture recording part 2]
Suggested Readings:
- UDL Chapter 6
-
 07a - Gradients and Backpropagation
07a - Gradients and Backpropagation
tl;dr: In this lecture we show how to efficienctly calculate gradients over more complex functions like deep neural networks using backpropagation. We also show an example simple implementation in the accompanying Jupyter notebook.
[slides] [jupyter notebook] [Lecture Part 1 - Scalar Gradient Descent] [Lecture Part 2 - Review Jupyter Notebook] [Lecture Part 3 - Matrix Gradient Descent]
Suggested Readings:
- UDL Sections 7.1 - 7.4
-
 07b - Initialization
07b - Initialization
tl;dr: In this lecture we talk about weight initialization and how it can impact the training results. We'll also go back and finish model fitting with the Adam optimizer. We'll also give some tips and tricks on how to efficiently scan and read research papers.
[slides] [lecture recording] [how to read research papers] [recording - how to read research paper]
Suggested Readings:
- UDL Sections 7.5 - 7.6
-
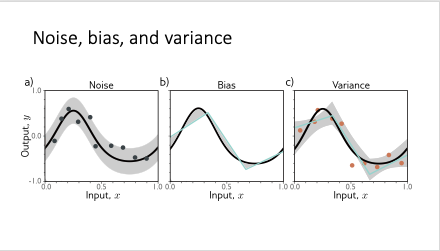 08 - Measuring Performance
08 - Measuring Performance
tl;dr: We look at measuring model training performance, the importance of test sets as well as how noise, bias and variance play a role in training outcomes.
[slides] [lecture recording]
Suggested Readings:
- UDL Chapter 8
-
 09 - Regularization
09 - Regularization
tl;dr: We explain explicit and implicit regularization techniques and how they help generalize models.
[slides] [lecture recording]
Suggested Readings:
- UDL Chapter 9
-
 10 - Convolutional Neural Networks
10 - Convolutional Neural Networks
tl;dr: We cover 1D and 2D convolutional neural networks along with subsampling and upsampling operations.
[slides] [lecture recording]
Suggested Readings:
- UDL Chapter 10
-
 11 - Residual Networks
11 - Residual Networks
tl;dr: In this lecture we introduce residual networks, the types of problems they solve, why we need batch normalization and then review some example residual network architectures.
[slides]
Unfortunately the lecture recording cut off after 1 minute. I will try to re-record it at some point.
Suggested Readings:
- UDL Chapter 11
-
 11a - Recurrent Neural Networks
11a - Recurrent Neural Networks
tl;dr: In this lecture we introduce recurrent neural networks, starting the plain vanilla RNN, the problem of vanishing gradients, LSTM and GRU and batch normalization.
[slides] [lecture recording]
Suggested Readings:
- UDL Chapter 11
-
 12 - Transformers
12 - Transformers
tl;dr: In this lecture we cover the transformer architecture, starting with the motivation that required a new type of model, the concept and implementation of self-attention and then the full transformer architecture for encoder, decoder and encoder-decoder type models.
[slides] [lecture recording]
Suggested Readings:
- UDL Chapter 12
- Optional The Illustrated Transformer
-
 13 - Transformers Part 2
13 - Transformers Part 2
tl;dr: In this lecture we continue to review the transformer architecture. We continue the discussion of decoders and encoder-decoder architectures, then discuss scaling to large contexts and then tokenization and embedding.
[slides] [lecture recording]
Suggested Readings:
- UDL Chapter 12
- Optional The Illustrated Transformer
-
 14 -- Vision & Multimodal Transformers
14 -- Vision & Multimodal Transformers
tl;dr: In this lecture we'll cover vision and multimodal transformers as a survey of three papers.
[slides] [lecture recording]
Suggested Readings:
- See slides for references
-
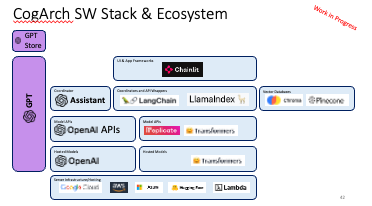 15 -- Improving LLM Perf
15 -- Improving LLM Perf
tl;dr: In this lecture we talk about ways to improve LLM performance short of retraining or finetuning. We cover more sophisticated prompt strategies, retrieval augmentation and cognitive architectures building systems and agents based on LLMs.
[slides] [lecture recording]
Suggested Readings:
- See slides for references
-
 16 - Parameter Efficient Fine Tuning
16 - Parameter Efficient Fine Tuning
tl;dr: In this lecture we'll do a quick review of full model fine tuning then review the parameter efficient finetuning techniques Low Rank Adaptation and Prompt Tuning.,
[slides] [lecture recording]
Suggested Readings: References are in the lecture slides.
-
 17 -- Unsupervised Learning and GANs
17 -- Unsupervised Learning and GANs
tl;dr: In this lecture we revisit the concept of unsupervised learning in the context of generative models. We will then dive into Generative Adversarial Networks (GANs) and their applications. We will also discuss the challenges and limitations of GANs and some of the recent advances in the field.
[slides] [lecture recording]
Suggested Readings:
- UDL Chapters 14 and 15
-
 18 - Variational Autoencoders (VAEs)
18 - Variational Autoencoders (VAEs)
tl;dr: In this lecture we dive into Variational Autoencoders or VAEs. We start by looking at autoencoders and their ability to reduce dimensions of inputs into a latent space. We'll see why they don't make good generative models and then generalize to VAEs. We'll finish with some examples of generative output of VAEs.
[slides]
Suggested Readings:
- Understanding Variational Autoencoders
- UDL Chapter 17 (optional)
Unfortunately the lecture recorded with no sound, so there is no lecture recording.
-
 19 -- Diffusion Models
19 -- Diffusion Models
tl;dr: Short text to discribe what this lecture is about.
[slides] [lecture recording]
Suggested Readings:
- Rocca, Understanding Diffusion Probabilistic Models
- UDL Chapter 18
-
 20 -- Graph Neural Networks
20 -- Graph Neural Networks
tl;dr: In this lecture we introduce graph neural networks, define matrix representations, how to do graph level classification and regression, and how to define graph convolutional network layers.
[slides] [lecture recording]
Suggested Readings:
- UDL Chapter 13
-
 21 - Reinforcement Learning
21 - Reinforcement Learning
tl;dr: We cover the basic concepts of reinforcement learning then review reinforcement learning from human feedback via the two seminal papers on the topic.
[slides]
Suggested Readings:
- UDL Chapter 19